Las instrucciones de máquina son conjunto de bits, agrupados en campos. Cada instrucción ocupa usualmente una palabra de memoria. Los campos típicos son: el campo de operación, que especifica la particular instrucción de que se trate (suma, multiplicación, comparación, etc.) y los campos de operandos, que indican cuáles son los operandos para esa operación. Esa estructura de bits es lo que llamamos formato de instrucción. El programa consiste de un conjunto de instrucciones.
Hay gran variedad de formatos: diferentes largos de instrucción (número de bits que componen la instrucción), diferente número de campos. Una misma arquitectura suele ofrecer varios formatos, según el tipo de operación; así por ejemplo, las operaciones aritméticas podrían ofrecer tres operandos: dos argumentos u operandos fuente y otro para indicar a dónde va a guardarse el resultado de la operación; mientras que, las instrucciones de salto o ruptura de la secuencia de ejecución pueden contener un solo operando: la dirección destino del salto. Otras instrucciones podrían no requerir ningún operando.
Aparte de los dos tipos de campos básicos mencionados: código de operación y operandos, se va a necesitar especificar cómo interpretar los operandos. Los valores de los operandos pueden residir en memoria o en registros, o podrían inclusive encontrarse en la propia instrucción. Necesitamos indicar a cuál de esas modalidades nos referimos (celda de memoria, registro del CPU, u operando inmediato -en la propia instrucción). Para el propósito de interpretar el tipo de operando se agregan, para cada operando, campos de modos de direccionamiento (y hay tal variedad de ellos que dedicaremos una lección aparte a su estudio).
Antes de enumerar la variedad de formatos que se ha utilizado en diferentes computadores, veamos algunas consideraciones que explican por qué la variedad de formatos. Desde el punto de vista del diseño del hardware que interpretará las instrucciones, es deseable la mayor simplicidad posible, así como la mayor regularidad. También conviene reducir la variedad de formatos, y sobre todo la variedad de largos de instrucción. Lo ideal es un repertorio con una sola longitud de instrucción. Mientras más variados e irregulares sean los formatos de instrucción, más complicada será la decodificación, más tiempo de cpu se utilizará en decodificar. Adicionalmente, como veremos en detalle en la lección sobre organización tubular (pipelining) los formatos regulares facilitan la ejecución superpuesta de varias instrucciones.
En relación al largo de instruccioón, una instrucción con tres operandos puede resultar intolerantemente larga. Téngase en cuenta que en principio lo que se indica en los campos de operandos es la dirección de memoria donde reside el operando, es decir dónde tomaremos su valor. Mientras más grande sea la memoria (un requisito sine qua non en cualquier computador de propósito general) más bits necesitaremos para expresar esas direcciones. Así, para direccionar 4 Giga, necesitamos campos de dirección de 32 bits, si usamos tres operandos necesitaríamos, sólo para operandos, 96 bits, más el campo de código operación y los campos de modos de direccilonamiento, sobrepasamos los 100 bits. Nada eficiente un computador con tal longitud de formato de instrucción: ineficiente en uso de memoria para programa e ineficiente en tiempo de captación y de decodificación.
En base a los mencionados requisitos de un repertorio regular y un formato de instrucción compacto, surgen todas las ideas que explican la variedad de soluciones que los arquitectos de computación han propuesto a lo largo de los años.
Volviendo a las operaciones aritméticas, no tenemos que pensar que obligatoriamente requerirán tres argumentos; podríamos, por ejemplo, disponer de sólo dos con la convención de que el resultado de la operación reemplazará el valor del primer operando (o del segundo). Es más, podríamos pensar en un sólo argumento, disponiendo de un registro especial que debe contener el otro operando y donde quedará además el resultado (es lo que llamamos un registro acumulador).
Lo primero ha sido reducir el número de direcciones en una instrucción. Consideremos una operacoión diádica, como sumar:
z:= x + y. En principio, necesitamos aportar tres direcciones, una para cada variable. Pero podríamos aportar sólo dos y sobre-entender que el resultado queda en una de las direcciones de los argumentos. Desde el punto de vista del programador esto trae dos consecuencias: uno, estar consciente de que uno de los argumentos será alterado (reemplazado por el resultado); dos, cuando finalmente necesite dejar el resultado en «z» reqerirá de otra instrucción para mover el resultado a ese lugar:
x:= x + y
z:= x
Continuando con la idea de reducir direcciones, podemos pensar en instrucciones de una sola dirección (aún para operaciones diádicas, como la suma). La idea es disponer de un registro especial, el «acumulador» el cual sirve como el valor de uno de los argumentos y también como lugar para dejar el resultado de la operación.
Así «Sumar y» se interpretará como Acc:= Acc + y
El programador habrá cargado previamente el acumulador con el otro argumento, y finalmente lo copiará a memoria:
Cargar x
Sumar y
Descargar en z
Aparentemente, no hemos ganado nada: en lugar de tener una larga instrucción, tenemos tres instrucciones, más cortas, pero que sumadas pueden ser aún más larga que la original. El esquema de acumulador sin embargo se justifica dada la naturaleza usual de los cálculos aritméticos. Considere por ejempo que se trata de evaluar la conocida fórmula: …
¿Podemos reducir aún más el número de direcciones? Sí, en efecto, existe las llamadas máquinas de cero dirección. En lugar del registro acumulador se introduce un stack en hardware. El stack es una estructura de memoria que sigue la disciplina FILO. EDn el caso de la máquina de cero direccioón, o máquina de stack, se implementa un stack en hardware, el cual además de soportar las operaciones de PUSH y POP, se conecta las dos celcdas más superficiales cde esa memoria FILO a los puertos de la UAL, de modo que en toda operación diádica se sobreentiende que ocurrirá entre las dos celdas más superficiales del stack, se hace POP a esos dos valores y PUSH al resultado recien obtenido.
*** Polish y Reverse Polish.
Atendiendo entonces al número de direcciones en las instrucciones diádicas las arquitecturas se clasifican en máquinas de 3 direcciones (3D), de dos (2D), de una (de acumulador) y de cero (de stack).
Otra corriente optó por minimizar el número de instrucciones que accesan la memoria. La famosa arquitectura MIPS de P&H y luego el standard RISC-V optaron por utilizar un banco de registros de propósito general (podían servir como acumuladores y para otros propósitos, como la indexación que estudiaremos más adelante). En estas arquitecturas sólo las instrucciones de carga y descarga de registros (LOAD, STORE) accesan la memoria, Las instrucciones diádicas operan con operandos previamente cargados en registros y dejan el resultado también en registros. En cierta forma volvemos a las tres direcciones, pero son direcciones de registros, ello significa que no causan un consumo inaceptable del espacio de la palabra de instrucción, siendo el banco de registros una pequeña (muy pequeña) memoria, digamos de 32 registros, basta 5 bits para seleccionar cada registro. Notemos que la idea del banco de registros no sólo viene a resolver un problema de uso del espacio de la palabra de instrucción sino. que minimiza el acceso a memorfia y por tangto permite procesamientos más rápidos que en una arquitectura con uno o varios accesos a memoria en cada instrución.
Estas direcciones de registros se suelen llamar medias direcciones (que sería mejor decir direcciones cortas, pues son mucho más cortas que la mitad de los bits de dirección de memoria). Se habla entonces de arquitectura de 3 ½D. Existe también arquitecturas de 2 ½D y -más escasa- de 1 ½D. Tambien nos encontramos con máquinas que ofrecen instruciones 1½D (esto es una dirección larga, de memoria, y una corta, de registro) y 2½D (dos direcciones largas y una corta).
De todas las variantes vistas, las más exitosas y en uso actualmente son las arquitecturas de 1D y 3 ½D.
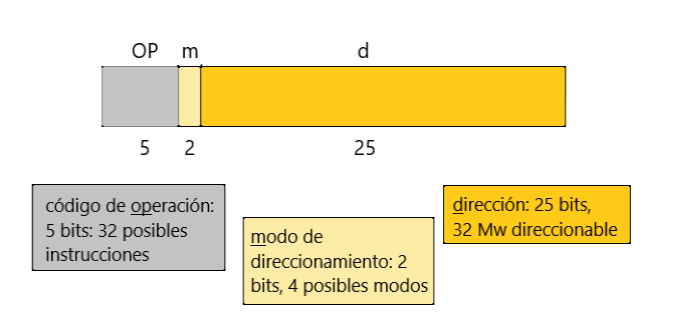
Aún las máquina 1D confrontan un problema de espacio del campo disponible para dirección en la palabra de instrucción. Considere una palabra de 32 bits. Si reservamos 5 bits para código de instrucción, queda 27 bits (máximo) para dirección. Si nuestra máquina tiene 32 Mega de memoria no podemos accesar las direcciones superiores a 2|27. En la lección siguiente, Modos de Direccionamiento, nos dedicamos a estudiar las varias soluciones que han ido apareciendo.
-
01 – Introducción
-
02 – Partes del Computador
-
03 – Memoria
-
04 – Registros
-
05 – Funcionamiento del Computador
-
06 – Formato de Instrucción
-
07 – Modos de Direccionamiento
-
08 – Repertorio de Instrucciones
-
09 – Trayectorias de Datos
-
10 – Entrada y Salida
-
11 – Velocidad de Procesamiento y Capacidad de Memoria
-
12 – Interrupciones
-
13 – Organización Tubular
-
14 – Memoria Cache
-
15 – Memoria Virtual
-
16 – Multiprocesadores
-
Post Template
Para fijar las ideas, con esta lección comenzaremos a utilizar esta columna para ilustrar el tema que venimos desarrollando con un ejemplo concreto. Utilizaremos una arquitectura sencila, desarrollada e implementada en la UC y que denominamos SUR. Más concretamente presentamos aquí la versión SUR-II.
FORMATO DE INSTRUCCIÓN SUR
Todas las instrucciones SUR ocupan una palabra de 32 bits, con un código de operación de 5 bits, un campo de 1 bit para modo de direccionamiento y los restantes 26 bits para dirección.
*** Figura por corregir
Las instrucciones de SUR son pues de una dirección (1D), y dispone, como ocurre en estas arquitecturas, de registro acumulador, el registro «A».
SUR no dispone de banco de registros, la mayoría de las instruccioones accesan memoria. Para reducir el cuello de botella que puede significar el tiempo de acceso a memoria principal, se propone el uso de un buen esquema de memoria cache (tema de la lección 14).
Unas pocas instrucciones no accesan la memoria, por ejemplo la instrucción HALT, que simplemente detiene la ejecucoión. Es una instrucción que todas las arquitecturas la incluyen aunque prácticamente no se ejecuta jamás. Pues bien, como HALT no necesita el campo de dirección, se utiliza ese campo para codificar allí unas cuantas instrucciones más que no necesiten accesar memoria. En la lección sobre Repertorio de Instrucciones veremos la lista de todas las instrucciones. Así el total de instrucciones diferentes es mayor de 32, aunque el campo OP sigue siendo de 5 bits.
Estas dimensiones permiten un repertorio de 32 instrucciones, ¿cierto?: veremos cómo agregar media docena más de instrucciones sin aumentar el tamaño de ese campo.
Con 1 bit para modo de direccionamiento disponemos de dos modos diferentes para accesar memoria. Un tema que continuaremos en la lección sig uiente.