Comparada con la velocidad del procesador central, el acceso a memoria es una operación lenta. En un mainframe de los 90s el tiempo de CPU estaba en los 10 ns, mientras el de la memoria principal en 100 ns, un orden de magnitud más lento (es lo que se ha denominado el «gap» cpu/memoria) . Si bien la velocidad de acceso a las memorias ha venido en aumento, también lo ha venido las prestaciones del CPU; el gap, en vez de reducirse, ha aumentado. Puede decirse, pues, que la memoria es el cuello de botella en el funcionamiento del computador. Justamente para aliviar esta disparidad de velocidades se introduce varias ténicas, la más importante entre ellas es la memoria cache («caché», según la RAE).
Las memorias, mientras más grandes, más lentas. Podemos verlo intuitivamente así: si la ciudad es muy grande, se taradará más en encontrar una dirección. Veámoslo ahora acercándonos a la tecnología de memoria: mientras más celdas de memoria, mayor complejidad en el circuito de decodificación, esto es en el circuito que, partiendo de la dirección, selecciona la celda correspondiente a esa dirección. Esa mayor complejidad del decodificador, el mayor número de etapas de lógica a atravesar por las señales, implica un mayor tiempo de acceso a las celdas de memoria. Hay otra razón para que las memorias grandes sean más lentas: para poder empaquetar muchos transistores en un mismo chip se utiliza una tecnología donde cada celda tiene el menor número posible de transistores, de hecho las llamadas Dinamic RAM (DRAM), utilizan un solo transistor por bit; pero, ello a costa de tener que «refrescar» dinámicamente (de allí el nombre), constantemente, los bits, pues esas memoria sencillas son, desafortunadamente, volátiles: el valor almacenado se pierde en pocos milisegundos, de nodo que se necesita leer y re-escribir cada bit a intervalos adecuados que garanticen la preservación de los datos. Las memorias estáticas, por otra parte, no necesitan de este refrescamiento, son mucho más rápidas, pero utilizan unos 7 transistores por bits, con lo cual la cantidad de bits para un determinado tamaño de CI es menor. Consecuentemente el precio por bit en estas memorias es mayor. Aún hay otra razón para que una memoria pequeña sea más rápida: unos pocos kilobytes se pueden empaquetar en el mismo chip del procesador y por tanto el acceso a esa memoria «cercana», no va a depender de buses externos, de comunicación entre chips, sino que dirección y datos viajan internamente, en el mismo CI..
Habiendo destacado el compromiso entre tamaño y velocidad, introducimos la idea de la memoria caché: una memoria muy rápida, pero de mucho menor tamaño que la memoria principal, «cercana» al CPU, la cual contendrá en cada momento la «parte activa» del programa en ejecución. El resto del programa y de datos que no caben en el caché residen en MM.
**mapeo
Cuando el programa solicita datos que no están en el cache, o cuando la secuencia de instrucciones hace un salto lejano (a zonas que no estaban en el cache) debe transferirse una nueva porción de los datos o del programa de la MM a la memoria rápida. Lo ideal es encontrar en el cache el dato o instrucción que corresponda a la dirección de MM especificada, pues se le accesará a gran velocidad; en cambio, si no está, habrá que esperar el tiempo que toma la MM, más lenta, en pasar ese dato o instrucción al caché. Cuando la dirección que se quiere accesar está copiada en el cache decimos que hubo un «hit», que vamos a traducir por «acierto»; cuando no lo está, que hubo un «miss», diremos una «falla». Lo ideal es obtener muchos «hits», o un alto «hit ratio». El hit ratio es el cociente de dividir el número de hits entre el número total de solicitudes a memoria, es decir entre el número de «hits» más «misses».
Hit Ratio(h) = Hit / (Hit + Miss)
Obtener un alto «hit ratio» va a depender de cómo implementemos el mapeo de direcciones, pero la verdadera razón por la cual la idea del caché funciona se debe, no tanto al hardware de mapeo y control del caché, sino a una propiedad intríseca de los programas: la localidad de las referencias. Se ha encontrado, empíricamente, que todos los programas (o la inmensa mayoría de los programas) ¡cuando accesan una localidad de memoria, la vuelven a accesar en el futuro cercano! ¿Por qué? pensemos en un lazo iterativo: cada vez que se da una vuelta al lazo se vuelve a accesar las mismas instruciones, y las mismas variables. Los coeficientes en una fórmula se accesan una y otra vez para multiplicarlos por la variable que preceden; el índice de un arreglo, se accesa a cada momento, tanto para indexar el arreglo, como para incrementarlo o decrementarlo, etc. Así pues, todos los programas accesan repetidas veces las mismas localidades de memoria. De modo que el simple hecho de traer a caché una localidad recien accesada, garantiza que cuando la volvamos a necesitar, ¡que será pronto!, ya estará en el caché. De ese modo estamos explotando la localidad temporal de las referencias. Resulta ahora que existe otra propiedad intrínseca de los progrgamas: la localidad espacial: ¡cuando accesamos una localidad de memoria -sea dato o instrucción- muy probablemente accesaremos, en el futuro cercano, las localidades vecinas! ¿Por qué?, pensemos de nuevo en el lazo iterativo, las instrucciones que componen el lazo están una a continuación de la otra, es decir, en localidades sucesivas de memoria. Pensemos en un arreglo (la estructura de datos más utilizada), sus elementos están contiguos, en localidades vecinas de memoria. Para explotar la propiedad de localidad espacial, simplemente cuando nos toca traer algo al caché, en lugar de traer exactamenbtre la palabra o byte de memoria que están solicitando, aprovechamos y traemos un bloque de bytes o palabras contiguas. Con ese simple expediente, tedremos siempre en caché la «parte activa» de los programas. Claro, llega el momentro en que el programa requiere un dato que pertenece a un nuevo arreglo por ejemplo, o que el programa salta a un segmento diferente; pues bien, en ese momento se producirá un miss, traeremos un nuevo bloque y, automáticamentre, comienza a reacomodarse el contenido del caché, empieza a cacharse la nueva parte activa del programa. El CPU encontrará que casi todo lo que va necesitando de memoria está en la memoria rápida, en el caché, muy cercano a él, y lo accesará a gran velocidad. En la práctica se ha encontrado que tamaños de bloque de 512 o de 1024 palabras son un buen compromiso entre el tamaño requerido para explotar adecuadamente la localidad espacial y la simplicidad necesaria para una implementación eficiente del mapeo en los tamaños típicos de las cachés actuales.
***mapeos
Mapeo de direcciones. Siendo la memoria principal más grande que la caché, en diferentes momentos un mismo bloque o porción del caché puede contener una u otra porción de MM, ¿cómo saber a qué dirección del caché corresponde una determinada dirección de la MM, y cómo saber si esa porcion de la MM está en ese momento copiada en el caché? Resolover este problema es el propósito del mapeo de direcciones. Hay varias soluciones. La más sencilla, conocida como mapeo directo, consiste en utilizar parte de los bits de dirección de MM para seleccionar el bloque del cache a donde irá a copiarse ese bloque de memoria. Ver figura:
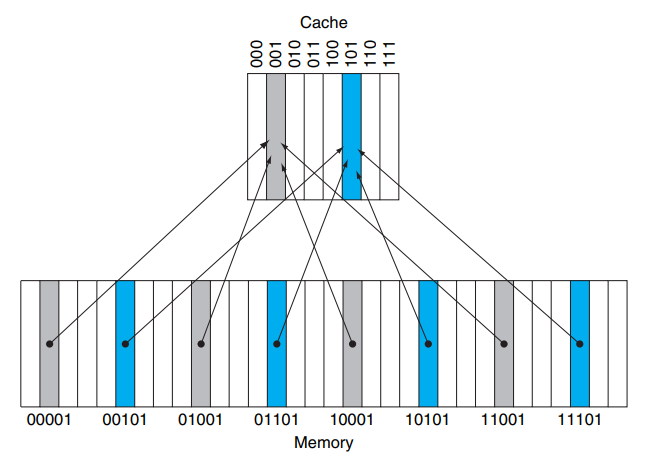
Todas las direcciones de MM, terminadas en 001 (las grises) les toca el bloque 001 del caché. Las direcciones terminadas en 101 (las azules) les toca el bloque 101 del caché. Y así con las terminadas en 000, en 010, 011, 100, 110 y 111: les corresponderá las respectivas direcciones en el caché. Podemos decir que 4 bloques de MM compiten por un bloque del caché. Observe cómo los 4 bloques grises se diferencias por sus dos primeros bits de dirección, igual ocurre con los cuatro bloques azules. Estos bists que permiten distinguir un bloque de otro se les conoce como «tag» («marca») del bloque.l
Diferentes bloque de la memoria les toca, cuando van a caché, residir en un mismo bloque de caché. Lo que tienen en común esos bloques son sus últimos bits de dirección, en el ejemplo simplificado de la figura, los tres últimos bits. El resto de los bits se guardarán en el cache, al lado del dato, para poder distinguir cuál de los posibles bloques de memoria principal que compiten por ese bloque de caché es el que está en ese momento presente. Esa porción de la dirección que guardamos en el cache se le conoce como «tag», o «marca». De modo que el tamaño de palabra en el caché será mayor que el tamaño de palabra de la MM: en el caché necesitamos agregar un campo para los tags. En la figura se requerirá 2 bits de tags. En una situación más realista (MM y caché más grandes), el campo de tag será bastante mayor.
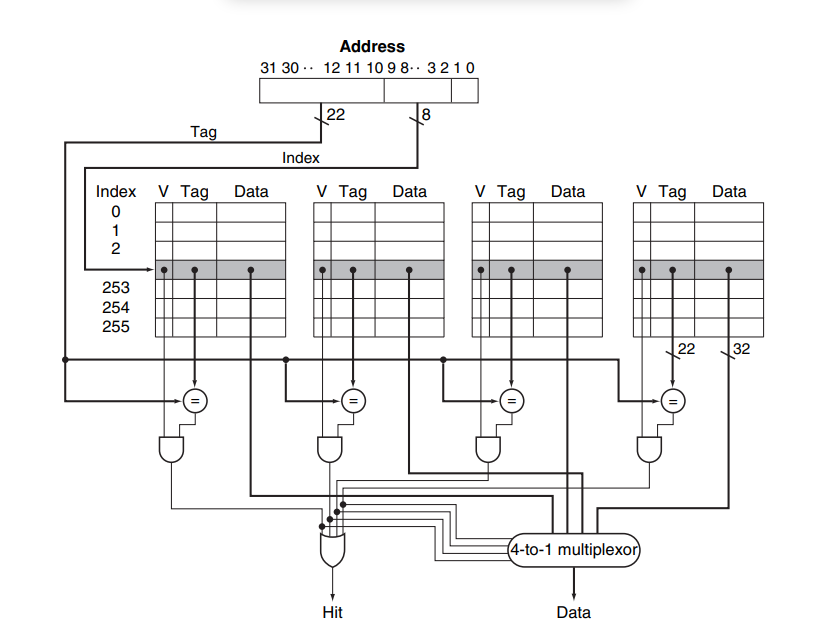
El mapeo directo, el esquema que acabamos de describir, es el más sencillo de implementar pero tiene el inconveniente de que al haber sitios fijos, pre-especificados, en el cache para cada bloque de MM se presenta el caso de que hay que ceder espacio para un nuevo bloque, siendo que probablemente aún convenía mantener en caché el bloque, pero que ahora debe ceder su puesto. Para atacar este problema y mejorar la eficiencia del caché (que en definitiva significa aumentar el hit ratio) se recurre a los cachés asociativos. En un cache full asociativo, un bloique de MM puede colocarse en cualquier bloque del caché, con ello la competencia por sitios en el caché desaparece; sólo si el caché está full (todos los bloques ocupados) se requerirá sacar un bloque previamente «cachado» para ceder espacio a un nuevo bloque de MM. Esta mejora en eficiencia es al precio de complicar el hardware de mapeo. Ahora en lugar de comparar un tag predeterminado, hay que comparar con todos los tags (pues el bloque de MM podría estar en cualquier bloque del caché). Para poder garantizar la velocidad que promete el caché, tal grupo de comparaciones se hace en paralelo, es decir se requiere tener tantos comparadores en hardware como bloques tenga el caché. Una solución intermedia -la más usada en la práctica- es un caché parcialmente asociativo: un bloque de MM puede residir en un conjunto de bloques del caché, pero no en todos. Esto simplifica el hardware de comparación, manteniendo parte del beneficio que da la flexibilidad de colocación.
Una situación que toca considerar es el caso en que hemos de traer un bloque determinado al caché, y no hay espacio (sea porque el caché está full, en caso de un mapeo full-asociativo; o sea porque el particular bloque donde puede ir esa porción de MM está ocupada, en caso de mapeo directo o parcialmente asociativo). No hay más remedio que sobreescribir un bloque. Si el bloque a reemplazar no ha sido alterada (porque era puro programa, o porque eran datos que no se han modificado), pues simplemente se re-escribe (sabemos que en MM hay copia de ello); si en cambio eran datos que se han modificado, habrá que respaldarlo a MM, sobrescribiendo la anterior versión de datos que se tenía alli con la versión más actualizada del caché. Para manejar esta situación, la escritura, se han aplicado dos diferentes estrategias: write-throug y wrtite-back. La estrategia write-through consiste en escribir tanto en el caché como en la MM cada vez que una instrucción ordene escribir en memoria (stores). De esa manera nunca la info en el caché será incoherente con MM, pero estaríamos accesando MM muy a menudo, La alternativa es atender los stores escribiendo sólo en caché, y actualizar memoria posteriormente, sólo cuando ese bloque tenga que ser reemplazado (ceder su espacio a otro bloque). Es la estrategia conocida como wrtite-back, con ella ahorramos muchos accesos a MM, pero no perdamos de vista que existirán lapsos con información en caché incoherente con la de MM, una situación que puede ser intolerable si la MM es compartida con otros CPUs o con procesos de E/S. Dejemos de lado esa preocupación, al menos por ahora.
90% de los accesos van al 10% de los datos
*** Ver P&H pag. 406
https://www.techtarget.com/whatis/definition/von-Neumann-bottleneck
*http://www.fdi.ucm.es/profesor/mendias/512/docs/tema13.pdf
https://www.geeksforgeeks.org/cache-memory-in-computer-organization/
La imagen del dentista y el instrumentl a mano.
Logramos una velocidad de acceso casi igual a la de la memoria más rápida y una capacidad igual a la de la memoria más grande.
Cachés separados para datos e instrucciones. Permitirá un incremento adicional de procesamientpo al poder superponer más operciones en pipelining (acceso a datos || captación de instrucciones).
Multi-niveles de cache: L1 (on chip), L2 (ouede ser compartido entre núcleos), L3.
Otros usos del cache: en multiprocesafores, Problema de invalidar.
El cache, o sus varios niveles, es totalmente transparente al programador; es un detalle de organización, no de arquitectura.
La idea de cache se extiende a MS y/MM, Bases de Dato, web. Allí aparecerán las mismas consifderaciones sobre mapeo y políticas de reemplazo. Volveremos a esas consideraciones en la lección sobre memoria virtual.
Memoria Intercalada
La memoria DRAM, la típicamente utilizada como MM, se organiza en módulos o bancos. Cada banco consta de cierta cantidad de chips de memoria. La división de memoria en bancos ha dado lugar a una ingeniosa y sencilla idea para aumentar el ancho de banda del acceso a la memoria.
Si tenemos dos bancos de memoria, digamos de 1 GW cada uno, tendemos a pesar que las palabras contiguas en cada bloque tienen direcciones sucesivas. Así en el primer bloique tendremos las palabras de direcció 0, 1, 2, 3,4 , hasta 1GW. Luego continúan las direcciones en el segundo bloque, desde 1GW +1 hasta 2 GW. Pues bién, qué pasa si decidimos más bien que las direcciones en el primer banco son las pares: 0, 2, 4… y en el segundo banco las impares: 1, 3, 5… Ocurrirá que podemos acceder a dos palabras contiguas, por ejemplo a las direcciones 200 y 201, simultáneamente. Esto es posible porque cada banco funciona independiente de los otros, cada uno tiene su propio registro de dirección y registro de contenidos. Consideremos ahora que en lugar de 2 bancos son 8 o 16, o más, con las direcciones distribuidas intercaladamente en los sucesivos bloques podemos accesar en paralelo tanta palabras contiguas como bancos tengamos en el sistema. Recordemos cuál es el interés en accesar bloques de palabras contiguas: que según la propiedad de localidad espacial cuando se accesa una palabra es muy probable que en el futuro inmediato se accesen palabras contiguas. De hecho los cachés funcionan gracias a esa propiedad, por ello las transferencia de MM a caché las hacemos por bloque de palabras contiguas. Es en ese sentido que la memoria intercalada viene a convefrtirse en una excelente soporte para la implementación de cache: el miss penalty, el retardo en el que se incurre cuando hay que traer un nuevo bloque de MM a caché, se verá reducido ya que el acceso al bloque y su transferencia -gracias al mayor ancho de banda ofrecido por la memoria intercalada- no será palabra por palabra sino grupos de palabra por grupos de palabra.
-
01 – Introducción
-
02 – Partes del Computador
-
03 – Memoria
-
04 – Registros
-
05 – Funcionamiento del Computador
-
06 – Formato de Instrucción
-
07 – Modos de Direccionamiento
-
08 – Repertorio de Instrucciones
-
09 – Trayectorias de Datos
-
10 – Entrada y Salida
-
11 – Velocidad de Procesamiento y Capacidad de Memoria
-
12 – Interrupciones
-
13 – Organización Tubular
-
14 – Memoria Cache
-
15 – Memoria Virtual
-
16 – Multiprocesadores
-
Post Template